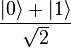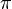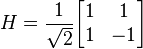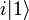Parallel Computation | Pengantar Thread Programming

Dalam pemrograman komputer, sebuah thread adalah informasi terkait dengan penggunaan sebuah program tunggal yang dapat menangani beberapa pengguna secara bersamaan. Dari program point-of-view, sebuah thread adalah informasi yang dibutuhkan untuk melayani satu pengguna individu atau permintaan layanan tertentu. Jika beberapa pengguna menggunakan program atau permintaan bersamaan dari program lain yang sedang terjadi, thread yang dibuat dan dipelihara untuk masing-masing proses. Thread memungkinkan program untuk mengetahui user sedang masuk didalam program secara bergantian dan akan kembali masuk atas nama pengguna yang berbeda. Salah satu informasi thread disimpan dengan cara menyimpannya di daerah data khusus dan menempatkan alamat dari daerah data dalam register. Sistem operasi selalu menyimpan isi register saat program interrupted dan restores ketika memberikan program kontrol lagi.
Sebagian besar komputer hanya dapat mengeksekusi satu instruksi program pada satu waktu, tetapi karena mereka beroperasi begitu cepat, mereka muncul untuk menjalankan berbagai program dan melayani banyak pengguna secara bersamaan. Sistem operasi komputer memberikan setiap program "giliran" pada prosesnya, maka itu memerlukan untuk menunggu sementara program lain mendapat giliran. Masing-masing program dipandang oleh sistem operasi sebagai suatu tugas dimana sumber daya tertentu diidentifikasi dan terus berlangsung. Sistem operasi mengelola setiap program aplikasi dalam sistem PC (spreadsheet, pengolah kata, browser Web) sebagai tugas terpisah dan memungkinkan melihat dan mengontrol item pada daftar tugas. Jika program memulai permintaan I / O, seperti membaca file atau menulis ke printer, itu menciptakan thread. Data disimpan sebagai bagian dari thread yang memungkinkan program yang akan masuk kembali di tempat yang tepat pada saat operasi I / O selesai. Sementara itu, penggunaan bersamaan dari program diselenggarakan pada thread lainnya. Sebagian besar sistem operasi saat ini menyediakan dukungan untuk kedua multitasking dan multithreading. Mereka juga memungkinkan multithreading dalam proses program agar sistem tersebut disimpan dan menciptakan proses baru untuk setiap thread.
Static Threading
Teknik ini biasa digunakan untuk komputer dengan chip multiprocessors dan jenis komputer shared-memory lainnya. Teknik ini memungkinkan thread berbagi memori yang tersedia, menggunakan program counter dan mengeksekusi program secara independen. Sistem operasi menempatkan satu thread pada prosesor dan menukarnya dengan thread lain yang hendak menggunakan prosesor itu.
Mekanisme ini terhitung lambat, karenanya disebut dengan static. Selain itu teknik ini tidak mudah diterapkan dan rentan kesalahan. Alasannya, pembagian pekerjaan yang dinamis di antara thread-thread menyebabkan load balancing-nya cukup rumit. Untuk memudahkannya programmer harus menggunakan protocol komunikasi yang kompleks untuk menerapkan scheduler load balancing. Kondisi ini mendorong pemunculan concurrency platforms yang menyediakan layer untuk mengkoordinasi, menjadwalkan, dan mengelola sumberdaya komputasi paralel.
Sebagian platform dibangun sebagai runtime libraries atau sebuah bahasa pemrograman paralel lengkap dengan compiler dan pendukung runtime-nya.
Dynamic Multithreading
Teknik ini merupakan pengembangan dari teknik sebelumnya yang bertujuan untuk kemudahan karena dengannya programmer tidak harus pusing dengan protokol komunikasi, load balancing, dan kerumitan lain yang ada pada static threading. Concurrency platform ini menyediakan scheduler yang melakukan load balacing secara otomatis. Walaupun platformnya masih dalam pengembangan namun secara umum mendukung dua fitur : nested parallelism dan parallel loops. Nested parallelism memungkinkan sebuah subroutine di-spawned (ditelurkan dalam jumlah banyak seperti telur katak) sehingga program utama tetap berjalan sementara subroutine menghitung hasilnya. Sedangkan parallel loops seperti halnya fungsi for namun memungkinkan iterasi loop dilakukan secara bersamaan.